Build a Retrieval Augmented Generation (RAG) App
One of the most powerful applications enabled by LLMs is sophisticated question-answering (Q&A) chatbots. These are applications that can answer questions about specific source information. These applications use a technique known as Retrieval Augmented Generation, or RAG.
This tutorial will show how to build a simple Q&A application over a text data source. Along the way we’ll go over a typical Q&A architecture and highlight additional resources for more advanced Q&A techniques. We’ll also see how LangSmith can help us trace and understand our application. LangSmith will become increasingly helpful as our application grows in complexity.
If you're already familiar with basic retrieval, you might also be interested in this high-level overview of different retrieval techinques.
What is RAG?
RAG is a technique for augmenting LLM knowledge with additional data.
LLMs can reason about wide-ranging topics, but their knowledge is limited to the public data up to a specific point in time that they were trained on. If you want to build AI applications that can reason about private data or data introduced after a model's cutoff date, you need to augment the knowledge of the model with the specific information it needs. The process of bringing and inserting appropriate information into the model prompt is known as Retrieval Augmented Generation (RAG).
LangChain has a number of components designed to help build Q&A applications, and RAG applications more generally.
Note: Here we focus on Q&A for unstructured data. If you are interested for RAG over structured data, check out our tutorial on doing question/answering over SQL data.
Concepts
A typical RAG application has two main components:
Indexing: a pipeline for ingesting data from a source and indexing it. This usually happens offline.
Retrieval and generation: the actual RAG chain, which takes the user query at run time and retrieves the relevant data from the index, then passes that to the model.
Note: the indexing portion of this tutorial will largely follow the semantic search tutorial.
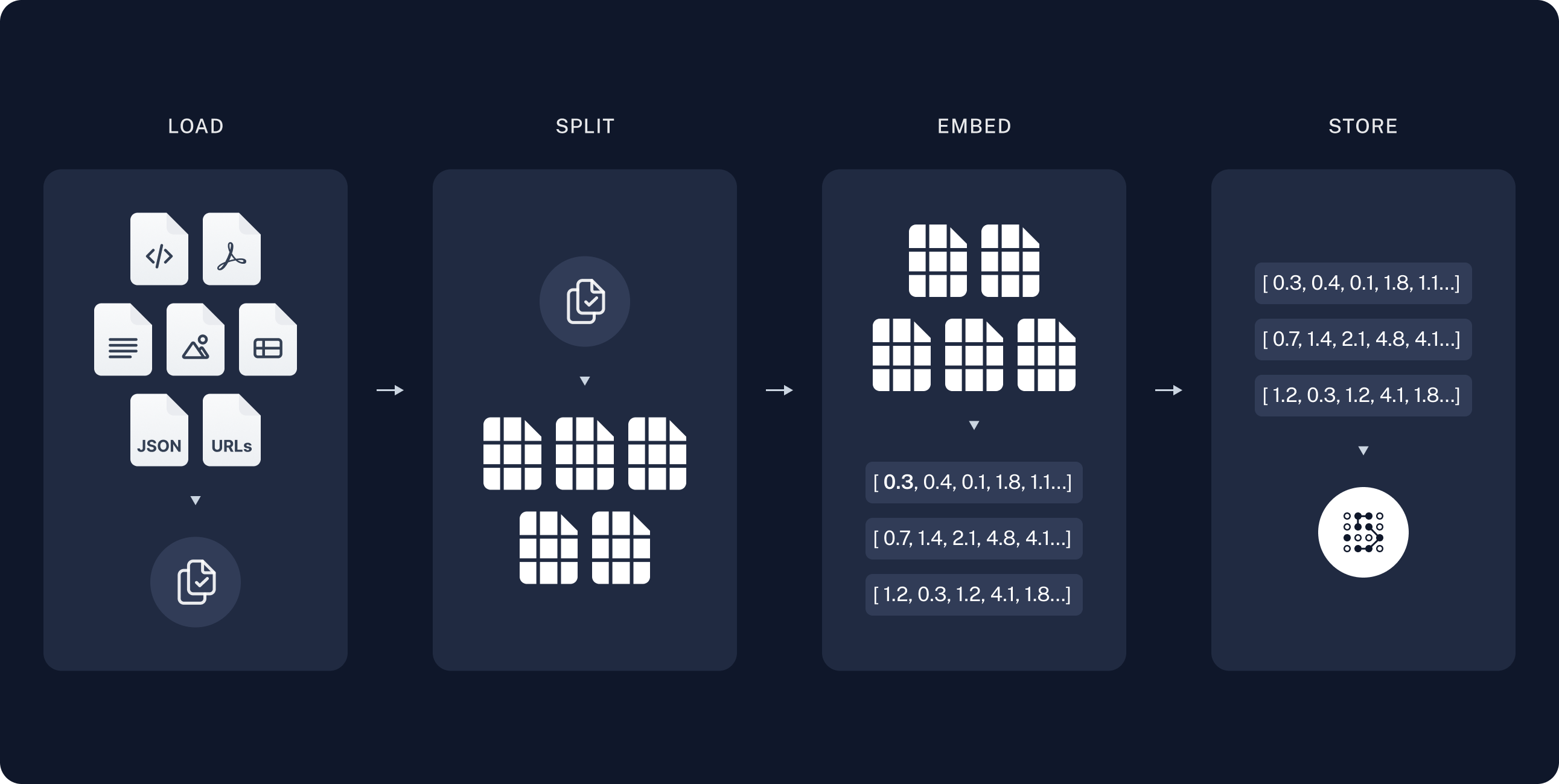
The most common full sequence from raw data to answer looks like:
Indexing
- Load: First we need to load our data. This is done with Document Loaders.
- Split: Text splitters break large
Documentsinto smaller chunks. This is useful both for indexing data and passing it into a model, as large chunks are harder to search over and won't fit in a model's finite context window. - Store: We need somewhere to store and index our splits, so that they can be searched over later. This is often done using a VectorStore and Embeddings model.
Retrieval and generation
- Retrieve: Given a user input, relevant splits are retrieved from storage using a Retriever.
- Generate: A ChatModel / LLM produces an answer using a prompt that includes both the question with the retrieved data
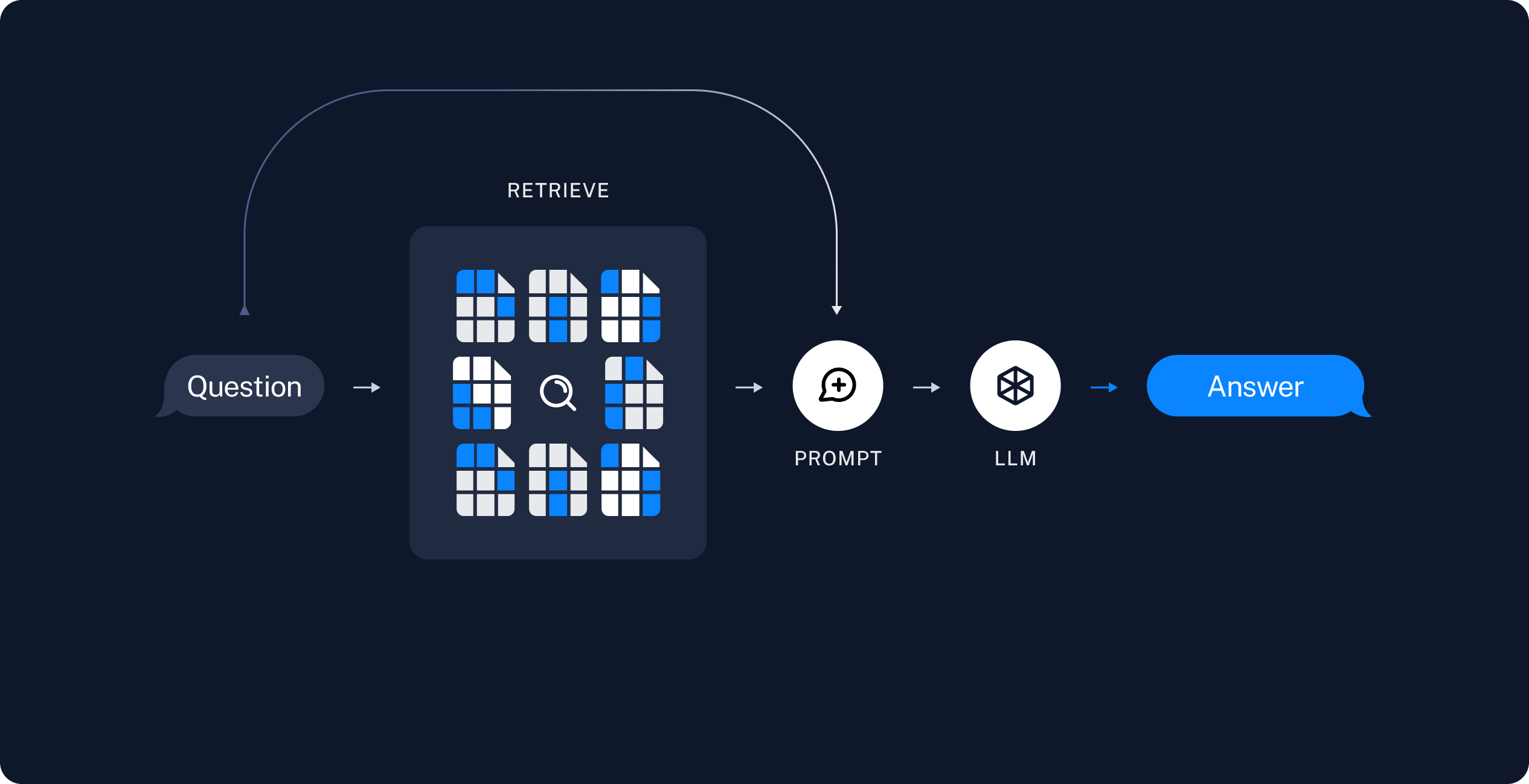
Once we've indexed our data, we will use LangGraph as our orchestration framework to implement the retrieval and generation steps.
Setup
Jupyter Notebook
This and other tutorials are perhaps most conveniently run in a Jupyter notebooks. Going through guides in an interactive environment is a great way to better understand them. See here for instructions on how to install.
Installation
This tutorial requires these langchain dependencies:
- Pip
- Conda
%pip install --quiet --upgrade langchain-text-splitters langchain-community
conda install langchain-text-splitters langchain-community -c conda-forge
For more details, see our Installation guide.
LangSmith
Many of the applications you build with LangChain will contain multiple steps with multiple invocations of LLM calls. As these applications get more complex, it becomes crucial to be able to inspect what exactly is going on inside your chain or agent. The best way to do this is with LangSmith.
After you sign up at the link above, make sure to set your environment variables to start logging traces:
export LANGCHAIN_TRACING_V2="true"
export LANGCHAIN_API_KEY="..."
Or, if in a notebook, you can set them with:
import getpass
import os
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
Components
We will need to select three components from LangChain's suite of integrations.
A chat model:
- OpenAI
- Anthropic
- Azure
- AWS
- Cohere
- NVIDIA
- FireworksAI
- Groq
- MistralAI
- TogetherAI
pip install -qU langchain-openai
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o-mini")
pip install -qU langchain-anthropic
import getpass
import os
os.environ["ANTHROPIC_API_KEY"] = getpass.getpass()
from langchain_anthropic import ChatAnthropic
llm = ChatAnthropic(model="claude-3-5-sonnet-20240620")
pip install -qU langchain-openai
import getpass
import os
os.environ["AZURE_OPENAI_API_KEY"] = getpass.getpass()
from langchain_openai import AzureChatOpenAI
llm = AzureChatOpenAI(
azure_endpoint=os.environ["AZURE_OPENAI_ENDPOINT"],
azure_deployment=os.environ["AZURE_OPENAI_DEPLOYMENT_NAME"],
openai_api_version=os.environ["AZURE_OPENAI_API_VERSION"],
)
pip install -qU langchain-google-vertexai
# Ensure your VertexAI credentials are configured
from langchain_google_vertexai import ChatVertexAI
llm = ChatVertexAI(model="gemini-1.5-flash")
pip install -qU langchain-aws
# Ensure your AWS credentials are configured
from langchain_aws import ChatBedrock
llm = ChatBedrock(model="anthropic.claude-3-5-sonnet-20240620-v1:0",
beta_use_converse_api=True)
pip install -qU langchain-cohere
import getpass
import os
os.environ["COHERE_API_KEY"] = getpass.getpass()
from langchain_cohere import ChatCohere
llm = ChatCohere(model="command-r-plus")
pip install -qU langchain-nvidia-ai-endpoints
import getpass
import os
os.environ["NVIDIA_API_KEY"] = getpass.getpass()
from langchain_nvidia_ai_endpoints import ChatNVIDIA
llm = ChatNVIDIA(model="meta/llama3-70b-instruct")
pip install -qU langchain-fireworks
import getpass
import os
os.environ["FIREWORKS_API_KEY"] = getpass.getpass()
from langchain_fireworks import ChatFireworks
llm = ChatFireworks(model="accounts/fireworks/models/llama-v3p1-70b-instruct")
pip install -qU langchain-groq
import getpass
import os
os.environ["GROQ_API_KEY"] = getpass.getpass()
from langchain_groq import ChatGroq
llm = ChatGroq(model="llama3-8b-8192")
pip install -qU langchain-mistralai
import getpass
import os
os.environ["MISTRAL_API_KEY"] = getpass.getpass()
from langchain_mistralai import ChatMistralAI
llm = ChatMistralAI(model="mistral-large-latest")
pip install -qU langchain-openai
import getpass
import os
os.environ["TOGETHER_API_KEY"] = getpass.getpass()
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
base_url="https://api.together.xyz/v1",
api_key=os.environ["TOGETHER_API_KEY"],
model="mistralai/Mixtral-8x7B-Instruct-v0.1",
)
An embedding model:
- OpenAI
- Azure
- AWS
- HuggingFace
- Ollama
- Cohere
- MistralAI
- Nomic
- NVIDIA
- Fake
pip install -qU langchain-openai
import getpass
os.environ["OPENAI_API_KEY"] = getpass.getpass()
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
pip install -qU langchain-openai
import getpass
os.environ["AZURE_OPENAI_API_KEY"] = getpass.getpass()
from langchain_openai import AzureOpenAIEmbeddings
embeddings = AzureOpenAIEmbeddings(
azure_endpoint=os.environ["AZURE_OPENAI_ENDPOINT"],
azure_deployment=os.environ["AZURE_OPENAI_DEPLOYMENT_NAME"],
openai_api_version=os.environ["AZURE_OPENAI_API_VERSION"],
)
pip install -qU langchain-google-vertexai
from langchain_google_vertexai import VertexAIEmbeddings
embeddings = VertexAIEmbeddings(model="text-embedding-004")
pip install -qU langchain-aws
from langchain_aws import BedrockEmbeddings
embeddings = BedrockEmbeddings(model_id="amazon.titan-embed-text-v2:0")
pip install -qU langchain-huggingface
from langchain_huggingface import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(model="sentence-transformers/all-mpnet-base-v2")
pip install -qU langchain-ollama
from langchain_ollama import OllamaEmbeddings
embeddings = OllamaEmbeddings(model="llama3")
pip install -qU langchain-cohere
import getpass
os.environ["COHERE_API_KEY"] = getpass.getpass()
from langchain_cohere import CohereEmbeddings
embeddings = CohereEmbeddings(model="embed-english-v3.0")
pip install -qU langchain-mistralai
import getpass
os.environ["MISTRALAI_API_KEY"] = getpass.getpass()
from langchain_mistralai import MistralAIEmbeddings
embeddings = MistralAIEmbeddings(model="mistral-embed")
pip install -qU langchain-nomic
import getpass
os.environ["NOMIC_API_KEY"] = getpass.getpass()
from langchain_nomic import NomicEmbeddings
embeddings = NomicEmbeddings(model="nomic-embed-text-v1.5")
pip install -qU langchain-nvidia-ai-endpoints
import getpass
os.environ["NVIDIA_API_KEY"] = getpass.getpass()
from langchain_nvidia_ai_endpoints import NVIDIAEmbeddings
embeddings = NVIDIAEmbeddings(model="NV-Embed-QA")
pip install -qU langchain-core
from langchain_core.embeddings import FakeEmbeddings
embeddings = FakeEmbeddings(size=4096)
And a vector store:
- In-memory
- AstraDB
- Chroma
- FAISS
- Milvus
- MongoDB
- PGVector
- Pinecone
- Qdrant
pip install -qU langchain-core
from langchain_core.vector_stores import InMemoryVectorStore
vector_store = InMemoryVectorStore(embeddings)
pip install -qU langchain-astradb
from langchain_astradb import AstraDBVectorStore
vector_store = AstraDBVectorStore(
embedding=embeddings,
api_endpoint=ASTRA_DB_API_ENDPOINT,
collection_name="astra_vector_langchain",
token=ASTRA_DB_APPLICATION_TOKEN,
namespace=ASTRA_DB_NAMESPACE,
)
pip install -qU langchain-chroma
from langchain_chroma import Chroma
vector_store = Chroma(embedding_function=embeddings)
pip install -qU langchain-community
from langchain_community.vectorstores import FAISS
vector_store = FAISS(embedding_function=embeddings)
pip install -qU langchain-milvus
from langchain_milvus import Milvus
vector_store = Milvus(embedding_function=embeddings)
pip install -qU langchain-mongodb
from langchain_mongodb import MongoDBAtlasVectorSearch
vector_store = MongoDBAtlasVectorSearch(
embedding=embeddings,
collection=MONGODB_COLLECTION,
index_name=ATLAS_VECTOR_SEARCH_INDEX_NAME,
relevance_score_fn="cosine",
)
pip install -qU langchain-postgres
from langchain_postgres import PGVector
vector_store = PGVector(
embedding=embeddings,
collection_name="my_docs",
connection="postgresql+psycopg://...",
)
pip install -qU langchain-pinecone
from langchain_pinecone import PineconeVectorStore
from pinecone import Pinecone
pc = Pinecone(api_key=...)
index = pc.Index(index_name)
vector_store = PineconeVectorStore(embedding=embeddings, index=index)
pip install -qU langchain-qdrant
from langchain_qdrant import QdrantVectorStore
from qdrant_client import QdrantClient
client = QdrantClient(":memory:")
vector_store = QdrantVectorStore(
client=client,
collection_name="test",
embedding=embeddings,
)
Preview
In this guide we’ll build an app that answers questions about the website's content. The specific website we will use is the LLM Powered Autonomous Agents blog post by Lilian Weng, which allows us to ask questions about the contents of the post.
We can create a simple indexing pipeline and RAG chain to do this in ~50 lines of code.
import bs4
from langchain import hub
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.documents import Document
from langchain_core.output_parsers import StrOutputParser
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langgraph.graph import START, StateGraph
from typing_extensions import List, TypedDict
# Load and chunk contents of the blog
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
all_splits = text_splitter.split_documents(docs)
# Index chunks and make retriever object
_ = vector_store.add_documents(documents=all_splits)
retriever = vector_store.as_retriever()
# Define prompt for question-answering
prompt = hub.pull("rlm/rag-prompt")
# Define state for application
class State(TypedDict):
question: str
context: List[Document]
answer: str
# Define application steps
def retrieve_docs(state: State):
retrieved_docs = retriever.invoke(state["question"])
return {"context": retrieved_docs}
def call_model(state: State):
docs_content = "\n\n".join(doc.page_content for doc in state["context"])
llm_chain = prompt | llm | StrOutputParser()
return {
"answer": llm_chain.invoke(
{"question": state["question"], "context": docs_content}
)
}
# Compile application and test
graph_builder = StateGraph(State).add_sequence([retrieve_docs, call_model])
graph_builder.add_edge(START, "retrieve_docs")
graph = graph_builder.compile()
response = graph.invoke({"question": "What is Task Decomposition?"})
print(response["answer"])
Task Decomposition is the process of breaking down a complicated task into smaller, manageable steps to facilitate easier execution and understanding. Techniques like Chain of Thought (CoT) and Tree of Thoughts (ToT) guide models to think step-by-step, allowing them to explore multiple reasoning possibilities. This method enhances performance on complex tasks and provides insight into the model's thinking process.
Check out the LangSmith trace.
Detailed walkthrough
Let’s go through the above code step-by-step to really understand what’s going on.
1. Indexing
This section is an abbreviated version of the content in the semantic search tutorial. If you're comfortable with document loaders, embeddings, and vector stores, feel free to skip to the next section on retrieval and generation
Loading documents
We need to first load the blog post contents. We can use DocumentLoaders for this, which are objects that load in data from a source and return a list of Document objects.
In this case we’ll use the
WebBaseLoader,
which uses urllib to load HTML from web URLs and BeautifulSoup to
parse it to text. We can customize the HTML -> text parsing by passing
in parameters into the BeautifulSoup parser via bs_kwargs (see
BeautifulSoup
docs).
In this case only HTML tags with class “post-content”, “post-title”, or
“post-header” are relevant, so we’ll remove all others.
import bs4
from langchain_community.document_loaders import WebBaseLoader
# Only keep post title, headers, and content from the full HTML.
bs4_strainer = bs4.SoupStrainer(class_=("post-title", "post-header", "post-content"))
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs={"parse_only": bs4_strainer},
)
docs = loader.load()
assert len(docs) == 1
print(f"Total characters: {len(docs[0].page_content)}")
Total characters: 43131
print(docs[0].page_content[:500])
LLM Powered Autonomous Agents
Date: June 23, 2023 | Estimated Reading Time: 31 min | Author: Lilian Weng
Building agents with LLM (large language model) as its core controller is a cool concept. Several proof-of-concepts demos, such as AutoGPT, GPT-Engineer and BabyAGI, serve as inspiring examples. The potentiality of LLM extends beyond generating well-written copies, stories, essays and programs; it can be framed as a powerful general problem solver.
Agent System Overview#
In
Go deeper
DocumentLoader: Object that loads data from a source as list of Documents.
- Docs:
Detailed documentation on how to use
DocumentLoaders. - Integrations: 160+ integrations to choose from.
- Interface: API reference for the base interface.
Splitting documents
Our loaded document is over 42k characters which is too long to fit into the context window of many models. Even for those models that could fit the full post in their context window, models can struggle to find information in very long inputs.
To handle this we’ll split the Document into chunks for embedding and
vector storage. This should help us retrieve only the most relevant parts
of the blog post at run time.
As in the semantic search tutorial, we use a RecursiveCharacterTextSplitter, which will recursively split the document using common separators like new lines until each chunk is the appropriate size. This is the recommended text splitter for generic text use cases.
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # chunk size (characters)
chunk_overlap=200, # chunk overlap (characters)
add_start_index=True, # track index in original document
)
all_splits = text_splitter.split_documents(docs)
print(f"Split blog post into {len(all_splits)} sub-documents.")
Split blog post into 66 sub-documents.
Go deeper
TextSplitter: Object that splits a list of Documents into smaller
chunks. Subclass of DocumentTransformers.
- Learn more about splitting text using different methods by reading the how-to docs
- Code (py or js)
- Scientific papers
- Interface: API reference for the base interface.
DocumentTransformer: Object that performs a transformation on a list
of Document objects.
- Docs: Detailed documentation on how to use
DocumentTransformers - Integrations
- Interface: API reference for the base interface.
Storing documents
Now we need to index our 66 text chunks so that we can search over them at runtime. Following the semantic search tutorial, our approach is to embed the contents of each document split and insert these embeddings into a vector store. Given an input query, we can then use vector search to retrieve relevant documents.
We can embed and store all of our document splits in a single command using the vector store and embeddings model selected at the start of the tutorial.
document_ids = vector_store.add_documents(documents=all_splits)
print(document_ids[:3])
['608d0358-a031-4e4c-84f2-0495cd2da8dd', '304e7527-1aee-45a2-9077-b8b54dffd7f2', '4f638d04-f152-42ea-ac93-5ceb1d20631c']
Go deeper
Embeddings: Wrapper around a text embedding model, used for converting
text to embeddings.
- Docs: Detailed documentation on how to use embeddings.
- Integrations: 30+ integrations to choose from.
- Interface: API reference for the base interface.
VectorStore: Wrapper around a vector database, used for storing and
querying embeddings.
- Docs: Detailed documentation on how to use vector stores.
- Integrations: 40+ integrations to choose from.
- Interface: API reference for the base interface.
This completes the Indexing portion of the pipeline. At this point we have a query-able vector store containing the chunked contents of our blog post. Given a user question, we should ideally be able to return the snippets of the blog post that answer the question.
2. Retrieval and Generation
Now let’s write the actual application logic. We want to create a simple application that takes a user question, searches for documents relevant to that question, passes the retrieved documents and initial question to a model, and returns an answer.
Retrieval
First we need to define our logic for searching over documents.
LangChain defines a
Retriever interface
which wraps an index that can return relevant Documents given a string
query.
The most common type of Retriever is the
VectorStoreRetriever,
which uses the similarity search capabilities of a vector store to
facilitate retrieval. Any VectorStore can easily be turned into a
Retriever with VectorStore.as_retriever():
retriever = vector_store.as_retriever(search_type="similarity", search_kwargs={"k": 6})
retrieved_docs = retriever.invoke("What are the approaches to Task Decomposition?")
len(retrieved_docs)
6
print(retrieved_docs[0].page_content)
Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.
Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.
Results of this retrieval, including latency and other metadata, can be ovserved through the LangSmith trace.
Go deeper
Vector stores are commonly used for retrieval, but there are other ways to do retrieval, too.
Retriever: An object that returns Documents given a text query
- Docs: Further
documentation on the interface and built-in retrieval techniques.
Some of which include:
MultiQueryRetrievergenerates variants of the input question to improve retrieval hit rate.MultiVectorRetrieverinstead generates variants of the embeddings, also in order to improve retrieval hit rate.Maximal marginal relevanceselects for relevance and diversity among the retrieved documents to avoid passing in duplicate context.- Documents can be filtered during vector store retrieval using metadata filters, such as with a Self Query Retriever.
- Integrations: Integrations with retrieval services.
- Interface: API reference for the base interface.
Orchestration
Let’s put it all together into an application that takes a question, retrieves relevant documents, constructs a prompt, passes it into a model, and returns the output.
For generation, we will use the chat model selected at the start of the tutorial.
We’ll use a prompt for RAG that is checked into the LangChain prompt hub (here).
from langchain import hub
prompt = hub.pull("rlm/rag-prompt")
example_messages = prompt.invoke(
{"context": "(context goes here)", "question": "(question goes here)"}
).to_messages()
assert len(example_messages) == 1
print(example_messages[0].content)
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: (question goes here)
Context: (context goes here)
Answer:
We'll use LangGraph to tie together the retrieval and generation steps into a single application. This will bring a number of benefits:
- We can define our application logic once and automatically support multiple invocation modes, including streaming, async, and batched calls.
- We get streamlined deployments via LangGraph Platform.
- LangSmith will automatically trace the steps of our application together.
- We can easily add key features to our application, including persistence and human-in-the-loop approval, with minimal code changes.
To use LangGraph, we need to define three things:
- The state of our application;
- The nodes of our application (i.e., application steps);
- The "control flow" of our application (e.g., the ordering of the steps).
State:
The state of our application controls what data is input to the application, transferred between steps, and output by the application. It is typically a TypedDict, but can also be a Pydantic BaseModel.
For a simple RAG application, we can just keep track of the input question, retrieved context, and generated answer:
from langchain_core.documents import Document
from typing_extensions import List, TypedDict
class State(TypedDict):
question: str
context: List[Document]
answer: str
Nodes (application steps)
Let's start with a simple sequence of two steps: retrieval and generation.
from langchain_core.output_parsers import StrOutputParser
def retrieve_docs(state: State):
retrieved_docs = retriever.invoke(state["question"])
return {"context": retrieved_docs}
def call_model(state: State):
docs_content = "\n\n".join(doc.page_content for doc in state["context"])
llm_chain = prompt | llm | StrOutputParser()
return {
"answer": llm_chain.invoke(
{"question": state["question"], "context": docs_content}
)
}
Note that we use a small LCEL chain to tie together the prompt, chat model, and output parser.
Control flow
Finally, we compile our application into a single graph object. In this case, we are just connecting the retrieval and generation steps into a single sequence.
from langgraph.graph import START, StateGraph
graph_builder = StateGraph(State).add_sequence([retrieve_docs, call_model])
graph_builder.add_edge(START, "retrieve_docs")
graph = graph_builder.compile()
LangGraph also comes with built-in utilities for visualizing the control flow of your application:
from IPython.display import Image, display
display(Image(graph.get_graph().draw_mermaid_png()))

Do I need to use LangGraph?
LangGraph is not required to build a RAG application. Indeed, we can implement the same application logic through invocations of the individual components:
question = "..."
retrieved_docs = retriever.invoke(question)
docs_content = "\n\n".join(doc.page_content for doc in retrieved_docs)
prompt = prompt.invoke({"question": question, "context": formatted_docs})
answer = llm.invoke(prompt)
The benefits of LangGraph include:
- Support for multiple invocation modes: this logic would need to be rewritten if we wanted to stream output tokens, or stream the results of individual steps;
- Automatic support for tracing via LangSmith and deployments via LangGraph Platform;
- Support for persistence, human-in-the-loop, and other features.
Many use-cases demand RAG in a conversational experience, such that a user can receive context-informed answers via a stateful conversation. As we will see in the Conversational RAG tutorial, LangGraph's management and persistence of state simplifies these applications enormously.
Usage
Let's test our application! LangGraph supports multiple invocation modes, including sync, async, and streaming.
Invoke:
result = graph.invoke({"question": "What is Task Decomposition?"})
print(f'Context: {result["context"]}\n\n')
print(f'Answer: {result["answer"]}')
Context: [Document(id='4f638d04-f152-42ea-ac93-5ceb1d20631c', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 1585}, page_content='Fig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning#\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.\nTask Decomposition#\nChain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.'), Document(id='88c673f6-da72-4241-aece-5ad55fdbde6c', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 2192}, page_content='Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.\nTask decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.'), Document(id='18aac09d-8882-4735-a5e9-45c8d0e0cc92', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 29630}, page_content='Resources:\n1. Internet access for searches and information gathering.\n2. Long Term memory management.\n3. GPT-3.5 powered Agents for delegation of simple tasks.\n4. File output.\n\nPerformance Evaluation:\n1. Continuously review and analyze your actions to ensure you are performing to the best of your abilities.\n2. Constructively self-criticize your big-picture behavior constantly.\n3. Reflect on past decisions and strategies to refine your approach.\n4. Every command has a cost, so be smart and efficient. Aim to complete tasks in the least number of steps.'), Document(id='36583f07-fea9-4740-a071-8226498bbe1d', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 19373}, page_content="(3) Task execution: Expert models execute on the specific tasks and log results.\nInstruction:\n\nWith the input and the inference results, the AI assistant needs to describe the process and results. The previous stages can be formed as - User Input: {{ User Input }}, Task Planning: {{ Tasks }}, Model Selection: {{ Model Assignment }}, Task Execution: {{ Predictions }}. You must first answer the user's request in a straightforward manner. Then describe the task process and show your analysis and model inference results to the user in the first person. If inference results contain a file path, must tell the user the complete file path."), Document(id='11601040-620e-42ba-9c21-e8508fd75fdf', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 17804}, page_content='The AI assistant can parse user input to several tasks: [{"task": task, "id", task_id, "dep": dependency_task_ids, "args": {"text": text, "image": URL, "audio": URL, "video": URL}}]. The "dep" field denotes the id of the previous task which generates a new resource that the current task relies on. A special tag "-task_id" refers to the generated text image, audio and video in the dependency task with id as task_id. The task MUST be selected from the following options: {{ Available Task List }}. There is a logical relationship between tasks, please note their order. If the user input can\'t be parsed, you need to reply empty JSON. Here are several cases for your reference: {{ Demonstrations }}. The chat history is recorded as {{ Chat History }}. From this chat history, you can find the path of the user-mentioned resources for your task planning.'), Document(id='3402415d-7a36-49d2-a6f2-6abb0c68dd9f', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 17414}, page_content='Fig. 11. Illustration of how HuggingGPT works. (Image source: Shen et al. 2023)\nThe system comprises of 4 stages:\n(1) Task planning: LLM works as the brain and parses the user requests into multiple tasks. There are four attributes associated with each task: task type, ID, dependencies, and arguments. They use few-shot examples to guide LLM to do task parsing and planning.\nInstruction:')]
Answer: Task Decomposition is the process of breaking down a complex task into smaller, manageable steps, often utilizing techniques like Chain of Thought (CoT) to enhance performance in large language models (LLMs). It allows the model to think step-by-step, making it easier to tackle difficult tasks by transforming them into simpler sub-tasks. Additionally, methods like the Tree of Thoughts expand this by exploring multiple reasoning paths at each step.
Stream steps:
for step in graph.stream(
{"question": "What is Task Decomposition?"}, stream_mode="updates"
):
print(f"{step}\n\n----------------\n")
{'retrieve_docs': {'context': [Document(id='4f638d04-f152-42ea-ac93-5ceb1d20631c', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 1585}, page_content='Fig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning#\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.\nTask Decomposition#\nChain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.'), Document(id='88c673f6-da72-4241-aece-5ad55fdbde6c', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 2192}, page_content='Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.\nTask decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.'), Document(id='18aac09d-8882-4735-a5e9-45c8d0e0cc92', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 29630}, page_content='Resources:\n1. Internet access for searches and information gathering.\n2. Long Term memory management.\n3. GPT-3.5 powered Agents for delegation of simple tasks.\n4. File output.\n\nPerformance Evaluation:\n1. Continuously review and analyze your actions to ensure you are performing to the best of your abilities.\n2. Constructively self-criticize your big-picture behavior constantly.\n3. Reflect on past decisions and strategies to refine your approach.\n4. Every command has a cost, so be smart and efficient. Aim to complete tasks in the least number of steps.'), Document(id='36583f07-fea9-4740-a071-8226498bbe1d', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 19373}, page_content="(3) Task execution: Expert models execute on the specific tasks and log results.\nInstruction:\n\nWith the input and the inference results, the AI assistant needs to describe the process and results. The previous stages can be formed as - User Input: {{ User Input }}, Task Planning: {{ Tasks }}, Model Selection: {{ Model Assignment }}, Task Execution: {{ Predictions }}. You must first answer the user's request in a straightforward manner. Then describe the task process and show your analysis and model inference results to the user in the first person. If inference results contain a file path, must tell the user the complete file path."), Document(id='11601040-620e-42ba-9c21-e8508fd75fdf', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 17804}, page_content='The AI assistant can parse user input to several tasks: [{"task": task, "id", task_id, "dep": dependency_task_ids, "args": {"text": text, "image": URL, "audio": URL, "video": URL}}]. The "dep" field denotes the id of the previous task which generates a new resource that the current task relies on. A special tag "-task_id" refers to the generated text image, audio and video in the dependency task with id as task_id. The task MUST be selected from the following options: {{ Available Task List }}. There is a logical relationship between tasks, please note their order. If the user input can\'t be parsed, you need to reply empty JSON. Here are several cases for your reference: {{ Demonstrations }}. The chat history is recorded as {{ Chat History }}. From this chat history, you can find the path of the user-mentioned resources for your task planning.'), Document(id='3402415d-7a36-49d2-a6f2-6abb0c68dd9f', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 17414}, page_content='Fig. 11. Illustration of how HuggingGPT works. (Image source: Shen et al. 2023)\nThe system comprises of 4 stages:\n(1) Task planning: LLM works as the brain and parses the user requests into multiple tasks. There are four attributes associated with each task: task type, ID, dependencies, and arguments. They use few-shot examples to guide LLM to do task parsing and planning.\nInstruction:')]}}
----------------
{'call_model': {'answer': 'Task decomposition is the process of breaking a complex task into smaller, manageable steps to simplify its execution. This can be done using techniques like Chain of Thought (CoT) and Tree of Thoughts, which guide models to reason through problems step by step. In practice, it involves prompting models to identify subgoals or using specific instructions to outline tasks.'}}
----------------
Stream tokens:
for message, metadata in graph.stream(
{"question": "What is Task Decomposition?"}, stream_mode="messages"
):
print(message.content, end="|")
|Task| De|composition| is| the| process| of| breaking| down| a| complex| task| into| smaller|,| manageable| steps| to| make| it| easier| to| execute|.| It| often| utilizes| techniques| like| Chain| of| Thought| (|Co|T|)| or| Tree| of| Thoughts| to| enhance| reasoning| and| planning|.| This| allows| models| to| systematically| approach| difficult| tasks| and| clarify| their| thought| process|.||
For async invocations, use:
result = await graph.ainvoke(...)
and
async for step in graph.astream(...):
Note that by storing the retrieved context in the state of the graph, we recover sources for the model's generated answer. See this guide on returning sources for more detail.
Returning sources
Often in Q&A applications it's important to show users the sources that were used to generate the answer. LangChain's built-in create_retrieval_chain will propagate retrieved source documents to the output under the "context" key:
Go deeper
Chat models take in a sequence of messages and return a message.
- Docs
- Integrations: 25+ integrations to choose from.
- Interface: API reference for the base interface.
Customizing the prompt
As shown above, we can load prompts (e.g., this RAG prompt) from the prompt hub. The prompt can also be easily customized. For example:
from langchain_core.prompts import PromptTemplate
template = """Use the following pieces of context to answer the question at the end.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
Use three sentences maximum and keep the answer as concise as possible.
Always say "thanks for asking!" at the end of the answer.
{context}
Question: {question}
Helpful Answer:"""
custom_rag_prompt = PromptTemplate.from_template(template)
Next steps
We've covered the steps to build a basic Q&A app over data:
- Loading data with a Document Loader
- Chunking the indexed data with a Text Splitter to make it more easily usable by a model
- Embedding the data and storing the data in a vectorstore
- Retrieving the previously stored chunks in response to incoming questions
- Generating an answer using the retrieved chunks as context.
There’s plenty of features, integrations, and extensions to explore in each of the above sections. Along with the Go deeper sources mentioned above, good next steps include:
- Return sources: Learn how to return source documents
- Streaming: Learn how to stream outputs and intermediate steps
- Add chat history: Learn how to add chat history to your app
- Retrieval conceptual guide: A high-level overview of specific retrieval techniques
- Build a local RAG application: Create an app similar to the one above using all local components